SQL and Window Functions - a quick introduction
Since I use SQLs window function nearly on a daily basis. So there are a lot of introductions to this useful functionalty, that never got to the point IMHO. So I will try it better :).
Syntax
window_function (expression) OVER (
[ PARTITION BY expr_list ]
[ ORDER BY order_list ][ frame_clause ] )
Note: a window function may only used in the select part of your statement and not in the other parts like where. It will evaluated after the your query has collected all rows, meaning, that every filter process, where expression and so on is finished.
select sum(my_value) over () from my_table
Window Functions
As window_function (look at syntax) you can use some expressions, you already know from aggregate functions, like sum, avg, min, max, …. And the partition by seems to somehow grouping your data. I think that is the reason, why the first understanding of window functions often is like: it is some kind of group by expression. This way of thinking prevents the real understanding of what these expressions really are.
Lets come from the other side. Why are these functions called windows functions?
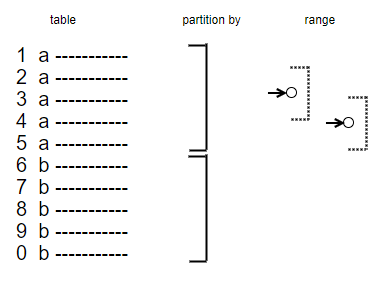
You see in this picture the data rows of your select or table. Using the partition by clause you are able to split your data rows into partitions, sets, groups, you name it. But thats not all. The last but most important thing is the window, the frame or the look at this partition, that selects a part of this partition dependent of the current row (see the array to the dot) you are in, that is used to feed the window_function. This last part (IMHO) is the thing that gave those window functions its name. This range could be but doesn’t need to be the whole partition. You are able to configure this window, but there are meaningfull default definitions of it.
complete table processing
Let this be our little test table test_table.
| id | numvalue | charvalue |
|---|---|---|
| 1 | 2 | C |
| 2 | 2 | B |
| 3 | 1 | A |
| 4 | 1 | E |
| 5 | 1 | G |
Then this delivers the complete sum of value column but not in one row, instead of for each row of mytable the sum is delivered.
SELECT id, sum(numvalue) OVER () AS mysum FROM mytable
And unlike group by aggregate expressions the result is not compressed.
| id | mysum |
|---|---|
| 1 | 7 |
| 2 | 7 |
| 3 | 7 |
| 4 | 7 |
| 5 | 7 |
with partition by only
Now lets begin to partition our table test_table. For each distinct value of numvalue we want to return the maximum of id.
SELECT id, numvalue, MAX( id ) OVER ( PARTITION BY numvalue ) AS mymax FROM mytable
| id | numvalue | mymax |
|---|---|---|
| 1 | 2 | 2 |
| 2 | 2 | 2 |
| 3 | 1 | 5 |
| 4 | 1 | 5 |
| 5 | 1 | 5 |
Note: Without any further configuration the window function processes each row for every partition. Therefore the range is always the complete partition.
with additional order by
Now the fun starts. Using an order by the window range within a partition is per default from the first row of the partition to the actual row regarding to the defined ordering. Now the sum delivers something completly different: it is a running sum. This is possible due to the ordering of the rows of a partition.
SELECT id, SUM( id ) OVER ( PARTITION BY numvalue ORDER BY id ) AS my_running_sum FROM mytable
| id | numvalue | my_running_sum |
|---|---|---|
| 1 | 2 | 1 |
| 2 | 2 | 3 |
| 3 | 1 | 3 |
| 4 | 1 | 7 |
| 5 | 1 | 12 |
Windows Functions
There is a huge set, dependent of the database system you are running on, which function you can use as window_function. Here is a subset of those. For the exact specification you should use your database vendors sql specification.
| window function | order by needed | description |
|---|---|---|
| avg | no | average value of a numeric column |
| row_number | yes | every row of the range of the partition is assigned with a sequential integer |
| count | no, but possible | Number of rows of the range in our partition. Since for non null values this seems to do the same thing like row_number, but use the function with the best fitting name. |
| sum | no, but possible | sum of numeric values of your partition in whole or a running sum |
The list is long.
numbering rows
Now we want each row numbered and starting each partition with 1. The order by defines the order of this sequential numbering.
SELECT numvalue, charvalue, row_number() OVER ( PARTITION BY numvalue ORDER BY charvalue ) AS rownum FROM mytable
| numvalue | charvalue | rownum |
|---|---|---|
| 2 | C | 2 |
| 2 | B | 1 |
| 1 | A | 1 |
| 1 | E | 2 |
| 1 | G | 3 |
Note: Just to make it clear: this order by does not reordering the output. But every of this numbering window functions need an order by.
The following functions are kind of numbering the rows with some slight but important differences.
| window function | description |
|---|---|
| rank | number the rows sequentially, but assigning equal numbers to equal values of the order by value. The next different value gets the value row_number would assign to it. Therefore you have a jump in those numbers. |
| dense_rank | Numbers the rows like rank but the next different value gets the next higher number. Therefore the numbering here is sequential. |
access to non actual row values
There are window functions to access a value of your partition. Keep in mind that using this you have to provide a order by and therefore the range per default from the first row of the partition to the actual row. Lets start with first_value and last_value.
Note: The returned value does not need to be one of the partition or ordering definition.
select id, numvalue, charvalue,
first_value(id) over (partition by numvalue order by charvalue) first_value_expr,
last_value(id) over (partition by numvalue order by charvalue) last_value_expr
from mytable
| id | numvalue | charvalue | first_value_expr | last_value_expr |
|---|---|---|---|---|
| 1 | 2 | C | 2 | 1 |
| 2 | 2 | B | 2 | 2 |
| 3 | 1 | A | 3 | 3 |
| 4 | 1 | E | 3 | 4 |
| 5 | 1 | G | 3 | 5 |
This strange behaviour of the last_value can be easily explained by the used range within the partition: first row to actual row.
Now two methods that do not seem to use the standard range definition as a default, but the complete partition.
| window function | description |
|---|---|
| lag | Reads a value from a previous row. You define the relative offset. |
| lead | Reads a value from a following row. You define the relative offset. |
select id,
lag(id,1) over (order by id) lag_expr,
lead(id,1) over (order by id) lead_expr
from mytable
order by id
| id | lag_expr | lead_expr |
|---|---|---|
| 1 | null | 2 |
| 2 | 1 | 3 |
| 3 | 2 | 4 |
| 4 | 3 | 5 |
| 5 | 4 | null |
with a frame definition
With the last examples it became somewhat clear, why the frame itself should be configurable as well. To define this range a quite complex sql construct is used.
You can e.g. here read Postgresql definition.
With this you can for instance configure your sum window function in a form, that it calculates the sum from the actual row and the two preceding rows and not from the complete partition.
select id,
sum(id) over () sum_expr,
sum(id) over (order by id rows between 2 preceding and current row) sum_expr_with_range
from mytable
order by id
| id | sum_expr | sum_expr_with_range |
|---|---|---|
| 1 | 15 | 1 |
| 2 | 15 | 3 |
| 3 | 15 | 6 |
| 4 | 15 | 9 |
| 5 | 15 | 12 |
In sum_expr is the normal complete partition sum result. In sum_expr_with_range there is the sum from the actual rows value the the two values before. For id = 4 this calculates 2 + 3 + 4 = 9.
Conclusion
Window Functions is a very neat tool in the SQL developers toolset. Use it, try it and then decide for concrete problems, if its the right way to go.